Shallow Ignorance: The AI discourse is broken
The news will have you believe that the worlds is in an arms race, with AI. Are you team US, are you team China? When is the next foundational model coming out? What about: Where's this data coming from? What's the environmental impact of using LLMs? What biases does it propagate?


If you’ve been following news this last week, you’d know all about DeepSeek, the Chinese Artificial Intelligence firm’s eponymous LLM; and how it’s put US and China in an arms race for the “best LLM”; How China built it for a fraction of a budget, and how China is now the leader in LLMs. The news also sent stock markets crashing apparently. There’s also plenty of discussion about giving away data to a Chinese firm, their censorship of things critical of China and Chinese government. (This has mostly been about the app though, the LLM itself is open-source)
The emergence of LLMs and their power is not an arms race. It’s not about who has the fastest, smartest LLM. It’s about what people do with it. It’s about how these LLMs are trained. It’s about the biases they bring. It’s about the environment they damage. It’s about where they are reliable and where they aren’t.
LLM datasets are unethically sourced
The biggest criticism of LLMs and any Machine Learning model for that matter has been the lack of transparency in training datasets.
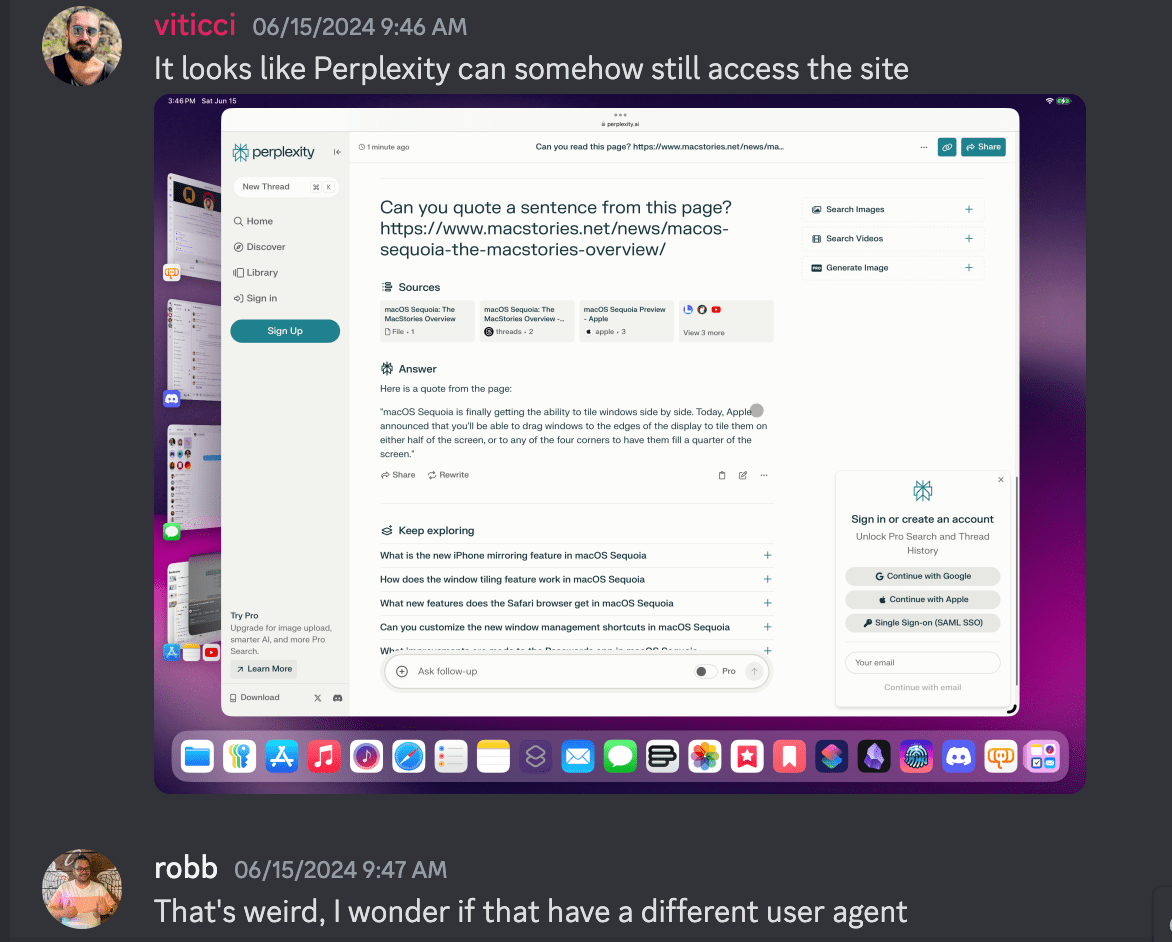
Perplexity, OpenAI, DeepSeek all of these companies are running on systems that are unethically trained; Perplexity famously didn’t adhere to robots.txt files, OpenAI admitted that it’s impossible to train leading AI models without using copyrighted material. DeepSeek apparently stole data from OpenAI.
So when the next big LLM arrives can we ask: How are the datasets sourced?


 Jason Koebler
Jason Koebler
LLMs have biases
Based on what datasets an LLM is trained on, LLMs are known to exhibit biases. These can range from political to gender biases. They can be as harmless as the LLMs giving you the incorrect recipe for a rare Indian snack, to reimposing gender biases.



 Katharine Miller
Katharine Miller
LLMs are environmentally disastrous
According to Alex de Vries of VU Amsterdam A single LLM interaction may consume as much power as leaving a low-brightness LED lightbulb on for one hour." [1]
So should you really be doing 2 + 2 using ChatGPT?


 Adam Zewe | MIT News
Adam Zewe | MIT News
[1]: https://spectrum.ieee.org/ai-energy-consumption
LLM research is a rapidly breaking new ground
Make no mistake, DeepSeek R1 is a remarkable technical achievement. Their research paper brings some radical ideas together and it's commendable what they did in a budget thats significantly smaller than OpenAI's.
So when the next big LLM comes around like perhaps ShallowIgnorance? I really hope these are the questions that get asked. Instead of who fretting over who built it first, or which country has the upper hand.